Case Study
Tripadvisor Enhances AI-Powered Trip Planning with Anyscale
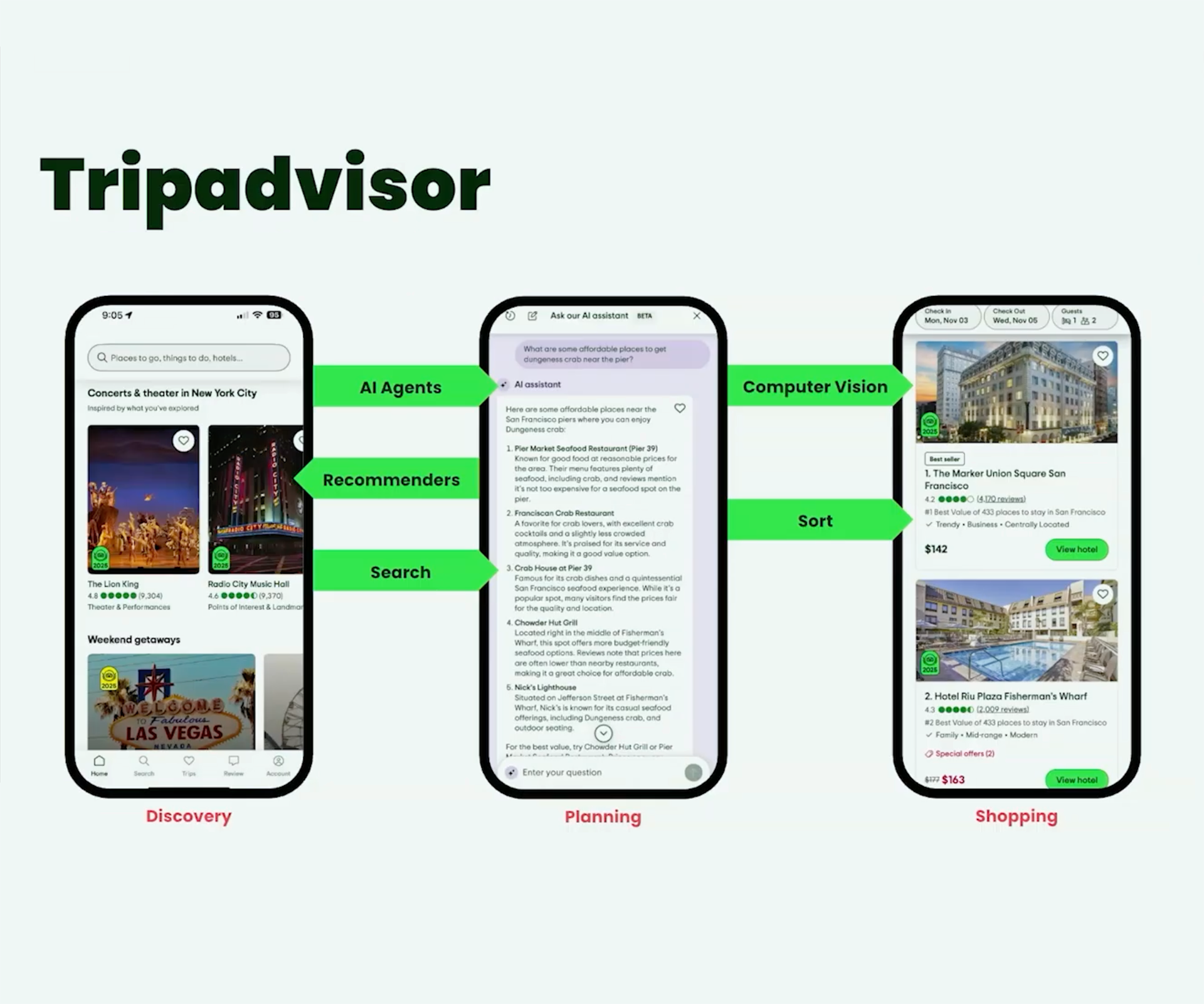
With Anyscale, Tripadvisor modernized its search and recommendation platform with a unified engine for batch and online inference. The platform enables more efficient multimodal embedding processing and lower infrastructure costs across workloads.
70%
Lower cost for batch inference
30%
Lower latency for online inference
80%
Less orchestration lines of code
Quick Takeaways
- 70% reduction in compute cost for image and review embedding workloads
- 30% lower latency and higher throughput for real-time inference using Ray Serve
- 80% reduction in lines of code for batch ML pipelines compared to Kubeflow
- 30% lower latency and higher throughput for real-time inference using Ray Serve
- Saved 7–10 months of platform engineering time by adopting Anyscale instead of building internal Ray infrastructure
Tripadvisor operates one of the world's largest travel platforms, helping hundreds of millions of travelers discover, plan, and book hotels, restaurants, attractions, tours, across destinations worldwide. AI and machine learning are deeply embedded across the product, powering semantic and lexical search, recommendations, and computer vision for image understanding working together to deliver personalized travel experiences.
To support these capabilities at global scale, Tripadvisor runs hundreds of offline machine learning workloads, hundreds of real-time inference models, and a rapidly growing number of AI microservices. As these systems expanded in scope and complexity, the company needed a more efficient way to build, operate, and scale machine learning without compromising the business requirements for both batch and real-time inference workloads.
LinkChallenges
To support its always growing AI footprint, Tripadvisor built an open-source, container-centric ML platform that layered Kubernetes, Kubeflow, Seldon ML Server and other services to help with scheduling and orchestration of those environments.
Over time, as workloads expanded into more data modalities, like running embedding generation for both images and text, and more recently using large language models (LLMs), the existing tooling started to become operationally and cost inefficient.
They wanted to solve several critical challenges:
Custom, boilerplate-heavy batch pipelines that constrained scaling: Offline machine learning workloads were primarily orchestrated using Kubeflow on Kubernetes. To productionize a workload like embedding generation on reviews, engineers had to decompose logic into containerized tasks, define explicit DAGs, and tightly bind application code, containers, and compute resources together. This approach introduced significant amounts of boilerplate code and made it difficult to express dynamic scaling or efficiently move data across CPU and GPU-based processing tasks within a single batch inference pipeline.
Increased complexity and latency in many-model systems: For online workloads, Tripadvisor relied on FastAPI paired with Seldon MLServer to deploy individual models. As AI systems evolved toward hybrid semantic search and other more complex decision-making systems, machine learning engineers needed to orchestrate multiple systems for a single inference request. This included running retrieval, re-ranking, feature lookups, and agent-based reasoning layered on top of core model inference. Managing this logic across separate systems added operational complexity and increased response latency.
Platform complexity created developer friction: As the scope of ML workloads expanded, the role of machine learning engineers shifted. Rather than handing models off to separate platform or application teams, ML engineers were expected to co-own end-to-end systems spanning batch pipelines, real-time services, and orchestration layers. Yet navigating the growing breadth of infrastructure services developers needed to work with significantly slowing the path from research to production.

Jay Destories | Sr Principal ML Engineer, Tripadvisor
LinkThe Solution
The rigidity, fragmentation, and platform complexity that the team was experiencing created a clear need for a more flexible compute abstraction that could support both batch and real-time workloads using a single programming model. To address these challenges, Tripadvisor standardized on Ray as its unified, Python-native engine for both batch and real-time workloads, and partnered with Anyscale to run it reliably and cost-effectively in production.
With Anyscale delivering a production-ready Ray platform from day one, Tripadvisor avoided an estimated 7–10 months of infrastructure build-out and quickly opened access to scalable distributed compute for ML engineers across teams
With Anyscale, Tripadvisor was able to:
Unify its stack and reduce operational complexity: Consolidating batch pipelines and real-time services onto a single Ray-based platform eliminated duplicated infrastructure, reduced system sprawl, and simplified how ML workloads are built, deployed, and monitored.
Lower infrastructure cost through better resource utilization: By running heterogeneous CPU and GPU workloads through a unified execution engine, Tripadvisor significantly improved hardware utilization and reduced idle capacity across large-scale embedding pipelines.
Accelerate time to value while increasing developer co-ownership: Instead of building and maintaining internal Ray platform support, Tripadvisor adopted Anyscale to move from proof of concept to production in weeks, enabling ML engineers and data scientists to co-own end-to-end systems without managing infrastructure complexity.
LinkUnified Stack, Less Operational Drag
By standardizing on Ray for both batch pipelines and real-time services, Tripadvisor eliminated the need to maintain separate orchestration layers, model servers, and container-centric execution patterns.
Previously, batch workloads required decomposing logic into tightly coupled Kubeflow DAGs. Online workloads required separate FastAPI services layered with Seldon ML Server for inference. Each system introduced its own configuration, scaling model, and operational overhead.
With Anyscale, both batch inference and real-time serving run on the same distributed compute framework. Machine learning engineers can express parallelism, scaling behavior, and resource requirements directly in Python, without defining Kubernetes primitives or stitching together multiple systems.
Jay Destories | Senior Principal Machine Learning Engineer, Tripadvisor
This unification reduced boilerplate code by approximately 80 percent in key pipelines and simplified how workloads are developed, deployed, and debugged across environments.
Jay Destories | Senior Principal Machine Learning Engineer, Tripadvisor
Operational visibility improved as well. Anyscale’s Ray dashboards and data-specific monitoring views were integrated into Tripadvisor’s existing Prometheus and Grafana stack. Both platform engineers and ML developers now share a consistent, real-time view of job execution, resource utilization, throughput, and failures across batch and serving systems.
LinkLower Infrastructure Cost Through Unified Compute
Unifying execution under Ray also enabled more efficient hardware utilization, particularly for heterogeneous pipelines that mix CPU- and GPU-intensive stages.
Tripadvisor’s image and review embedding pipelines process hundreds of millions of assets and serve as foundational features for semantic search, ranking, and personalization. Previously, these workloads relied on rigid pipeline stages with limited scheduling flexibility. In parallel, Tripadvisor introduced new geo-location embedding pipelines that combine names, descriptions, geographic hierarchies, and metadata into rich vector representations for recommendation and reranking models.
With Ray Data on Anyscale, the team decoupled CPU-heavy preprocessing from GPU-based embedding inference and dynamically scheduled workloads across heterogeneous resources. This significantly increased GPU utilization and reduced idle capacity. Daily embedding jobs now process approximately 100,000 new images, while large backfills scale across hundreds of millions of assets without requiring long-lived, overprovisioned clusters.

Sam Jenkins | Sr MLOps Engineer, Tripadvisor
Across key embedding generation pipelines, Tripadvisor achieved more than an 80 percent reduction in compute cost compared to previous Kubeflow-based implementations.
LinkFaster Time to Value and Greater Developer Co-Ownership
After validating Ray's performance and developer productivity benefits, Tripadvisor faced a strategic decision: whether to build and operate a production-grade Ray platform internally or adopt Anyscale as a managed platform. While Tripadvisor has deep expertise in Kubernetes and open source systems, the opportunity cost of building and maintaining a full Ray platform extended far beyond standing up clusters.
Sam Jenkins | Sr MLOps Engineer, Tripadvisor
By choosing Anyscale, Tripadvisor avoided months of internal platform engineering and gained immediate access to production-ready Ray clusters with built-in autoscaling, proactive spot instance handling, canary deployments, head node fault tolerance, integrated observability, role based access controls, and fine-grained cost reporting. Through native integration with Prometheus and Grafana, both platform engineers and ML teams could monitor Ray dashboards, optimize resource utilization, and debug operational issues using a consistent set of metrics.
The platform team transitioned from operating infrastructure components to providing a paved path for developers. Kubernetes primitives, including container lifecycles and workflow orchestration, were abstracted away. ML engineers no longer needed to manage cluster-level complexity and could instead focus on building and deploying AI systems in Python.
Sam Jenkins | Senior ML Ops Engineer, Tripadvisor
What began with machine learning engineers familiar with distributed systems is now expanding to onboard data scientists with less infrastructure expertise. By providing a unified execution model and shared observability, Anyscale increased co-ownership between platform and ML teams to continue accelerating our development to production lifecycle.
LinkWhat’s Next for Tripadvisor
Tripadvisor continues to expand its use of Ray and Anyscale across its machine learning platform. The team is migrating additional batch pipelines to Ray Data, consolidating real-time services on Ray Serve, and exploring advanced AI systems including LLM training and fine tuning, agent-based workflows and large-scale model retraining. They are also moving their existing feature store library from Spark on Kubernetes to Ray Data, with early results showing dramatic performance improvements.
With a flexible and scalable foundation in place, Tripadvisor is well positioned to support both today's production workloads and the next generation of AI-driven travel experiences.
