
Case Study
Coactive AI Builds a Multimodal Platform on Anyscale
Coactive AI now delivers real time multimodal insights across millions of images and videos, with faster model deployment, lower processing costs, and a cleaner, more scalable platform powered by Anyscale.
1
day from dev to prod for multimodal AI models
4x
lower per image processing cost
75%
lower GPU compute costs
Quick Takeaways
- 1 day to deploy new multimodal model endpoints, down from 1+ week
- 4× cheaper image processing vs. their previous compute stack
- 75% lower GPU cost, driven by fractional GPU allocation
- Multi-cloud (Azure + AWS), single pane of glass and consistent deployments
- Cleaner codebase, with ~25% fewer lines in service definitions
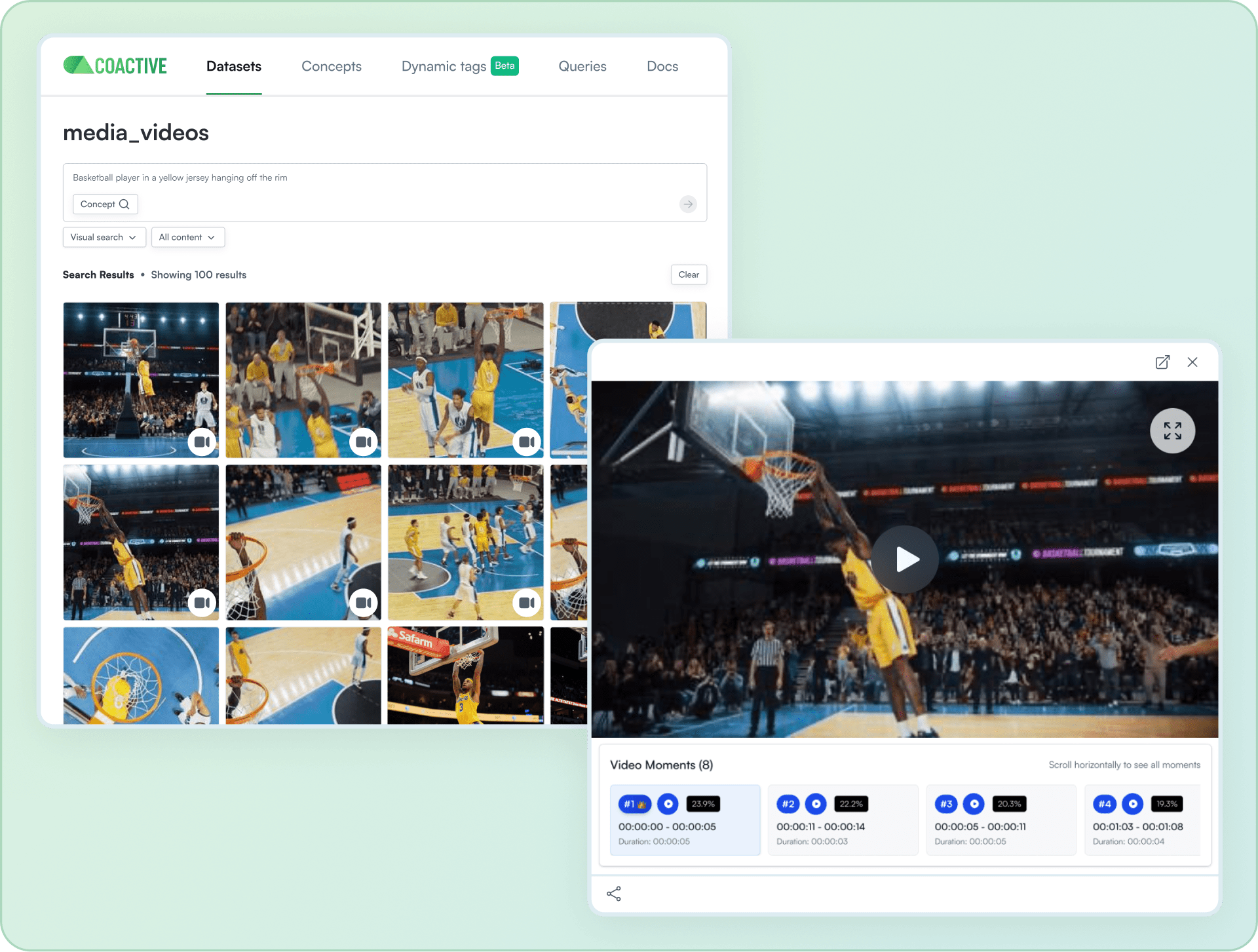
Coactive AI is reshaping visual content analytics by helping organizations turn massive image, video, and multimodal archives into searchable, trustworthy, and semantically rich datasets with their Multimodal AI Platform (MAP). Their platform makes foundation models practical for business users (e.g. marketing teams, product managers, analysts) and app developers by creating a rich semantic understanding of visual content for millions of assets at a time without requiring customers to fine-tune or operate large models themselves.
To deliver this experience to their retail, media and entertainment enterprise customers, Coactive AI needed a compute platform that could meet their multi-cloud – currently Azure and AWS – processing requirements as well as the ability to run securely within their account. They chose Anyscale to provide a scalable and future proof foundation for their multimodal processing requirements.
LinkChallenges
As Coactive AI’s customer base in multimodal-heavy industries like retail, media, and entertainment grew, the team needed a platform that could handle rising data-processing volumes, stay flexible enough to adopt the latest foundation models to deliver cutting-edge accuracy, all while being able to meet strict enterprise security requirements and service level agreements.
As they sought to enhance their platform, they wanted to solve for three major challenges:
Increasing costs from dual inference workload patterns: Mix of low-latency serving such as search and large-scale batch processing such as embedding refreshes, pushed the existing platform beyond its limits and led to continuous operational overhead to keep up with customer SLAs and rising costs from underutilized GPUs.
Week-long efforts to deploy and evaluate new models: When new VLMs and other multimodal AI became available, the onboarding test and evaluation was limited to the availability of two expert MLOps engineers, who could take a week or more to get new model running, limiting the speed of innovation.
Complexity in running workloads across clouds: Enterprise customers required data to remain within their preferred cloud provider to protect their IP. To meet these constraints without fragmenting their architecture, the Coactive team aimed to leverage their existing Kubernetes investments and build a portable AI platform.

Ross Morrow | Principal Engineer
LinkThe Solution
By partnering with Anyscale, Coactive gained a managed platform with a unified and scalable compute engine – powered by Ray – that offered the scalable and portable distributed processing they needed for their large-scale video and image workloads across AWS and Azure.
With Anyscale, Coactive AI is able to:
Reduce GPU costs by 75%: Fractional GPU allocations (e.g. 0.1 or 0.5 GPUs) that help increase workload density and fast autoscaling (2 → 50 GPUs) let the team more efficiently handle bursts efficiently without paying for idle capacity, driving a 75% reduction in GPU spend and a 4x drop in per-image processing cost.
Go from weeks to 1-day model deployments: Ray Serve’s Python-based deployment APIs make it easier for a wider range of developers to ship models, reducing full reliance on senior MLOps engineers. More developers can now contribute to data tagging accuracy improvements by being able to quickly test, evaluate, and use existing workflows to later on deploy new models to production.
Secure, multi-cloud deployments: Leveraging Anyscale’s Bring Your Own Cloud (BYOC) deployment on Coactive’s Kubernetes clusters across AWS and Azure keeps multimodal datasets within the desired cloud or region to meet compliance and customer requirements.
Ross Morrow | Principal Engineer
LinkGPU Efficiency & Cost Reduction
Coactive needed to process multimodal data, including images, video frames, text, and embeddings, at scale while keeping GPU costs under control. Their previous Kubernetes-based autoscaling system did not have native granular GPU allocations, which drove up compute spend during both ingestion bursts and normal operation.
Anyscale delivered major cost gains through fractional GPU allocations, allowing Coactive to pack multiple model replicas onto a single GPU and directly reduce the number of GPUs needed for the same workload.
Ross Morrow | Principal Engineer
Paired with elastic autoscaling, Anyscale enabled Coactive to scale from a handful of GPUs up to more than 50 during traffic spikes, then back down to near-zero idle capacity. This eliminated wasteful overprovisioning and led to an overall 4x cheaper per-image processing and an overall 75% reduction in GPU compute cost.
LinkReliable, Predictable Performance
Coactive's core user experience depends on predictable semantic search latency at 200+ requests per second. Their self hosted Ray Serve deployment delivered strong throughput, but suffered from latency variability, with p95 spikes reaching 30 seconds or more during peak periods.
Anyscale introduced SLA aware autoscaling using request target scaling, supported by internal queues and micro batching for smoother traffic handling. This combination stabilized latency even under bursty workloads and allowed Coactive to meet their SLAs without overprovisioning GPUs, improving both performance consistency and cost efficiency.
Coactive also gained clearer operational visibility from unified autoscaling signals, including QPS, backlog, replica health, and error rates. These insights helped their MLOps team diagnose issues quickly and maintain reliable performance across both ingestion and online inference workloads.
Ross Morrow | Principal Engineer
LinkPortable, Multi-Cloud Deployments
Coactive serves enterprises with strict data sovereignty and residency constraints. Video archives can reach terabytes in size, which makes it impractical and often non-compliant to move data outside specific cloud provider regions.
Anyscale's Bring Your Own Cloud (BYOC) model allowed Coactive to deploy Ray Serve directly inside their Kubernetes environments across both AWS and Azure. This ensured all multimodal content stayed within a trusted environment with no cross-cloud data transfers, allowed Coactive to meet customer-specific cloud requirements, and provided a consistent architecture across clouds.
This flexibility aligned perfectly with Coactive's cross-cloud and portable platform strategy and the compliance standards expected in media and retail industries they serve.
LinkDeveloper Velocity & Simpler Operations
Before Anyscale, deploying a new model (whether text, vision, or multimodal) required deep infrastructure context and significant engineering time. Coactive's applied AI engineers and platform team needed a faster, more ergonomic path to integrating and scaling new models.
With Anyscale, service definitions shrank to roughly 25% of their previous code size, which enabled more developers to safely modify and deploy Ray Serve endpoints.
Ross Morrow | Principal Engineer
Most importantly, Coactive saw a dramatic drop in time-to-production:
Ross Morrow | Principal Engineer
This acceleration, combined with Anyscale’s consistent autoscaling and debugging signals, gave Coactive a mature operational foundation without the overhead of running Ray Serve infrastructure themselves.
LinkWhat’s Next for Coactive AI
Coactive plans to expand support for new foundation models and architectures, including more advanced text, vision, and multimodal backbones that unlock richer semantic understanding for customers in media, retail, and trust and safety. The team is also strengthening the bridge between research and production by reducing redundant work, tightening governance, and accelerating the path from prototype to deployment.
Looking ahead, Coactive aims to scale its batch and streaming pipelines to support even larger archives and more complex customer workloads. By blending embeddings, classifiers, and temporal reasoning across video, they plan to deliver more real-time insights, support more diverse data types, and deepen the intelligence layer that helps enterprises interact with their media at scale.
