The Best Place to Build
and Run AI with Ray
From the creators of Ray – Anyscale gives you a platform to run and
scale all your ML and AI workloads, from data processing to training and inference.

Ray Summit 2025
Join fellow Ray practitioners for hands-on training, real world use case breakout sessions, product announcements, networking and more.
Ray is the Distributed Compute Engine for the AI Era
Ray is an open-source framework that helps developers scale data processing, training, and inference workloads from laptops to tens or thousands of nodes.
- Python-native. Distribute Python functions using familiar frameworks and data structures.
- Multimodal. Process all data modalities, including images, video, text, audio, tabular datasets, and more.
- Heterogeneous. Coordinate task execution across CPUs, GPUs, or other accelerators in a single cluster.
Anyscale is the Best Platform for Ray
Ready from day one to help you build faster, scale easier, and operate with confidence.
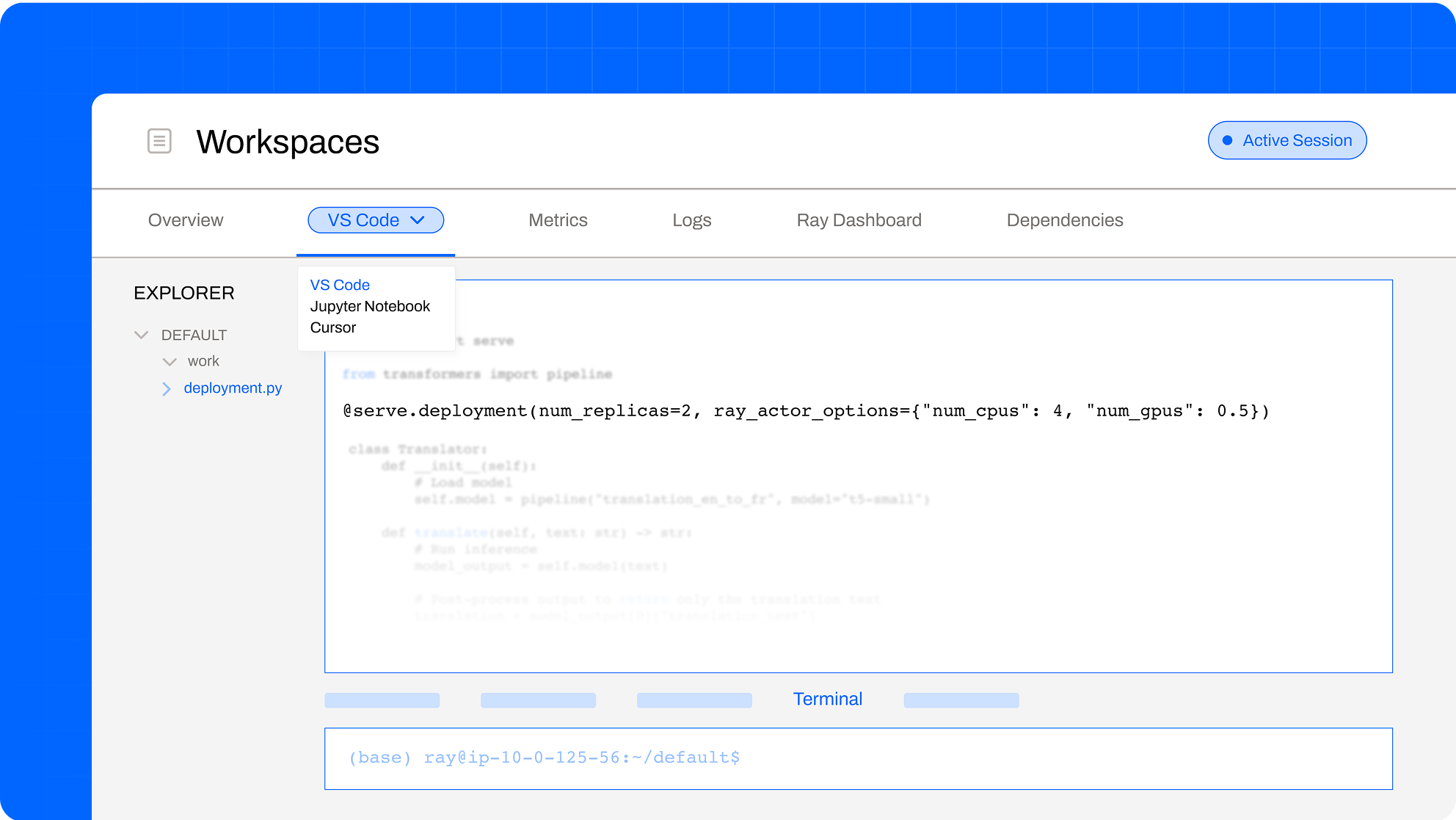
DEVELOPER AGILITY
Build. Debug. Deploy. Repeat.
Interactive dev console with advanced workload observability to help you debug quickly, and seamlessly transition from dev to prod.
Built-in IDE. Cloud-based, scalable dev environments with idle termination to reduce costs accessible via VSCode, Jupyter, and Cursor.
Workload Observability. Debug faster with profiling tools built for distributed workloads.
Dependency Management. Auto propagate container and uv dependencies across Ray nodes.
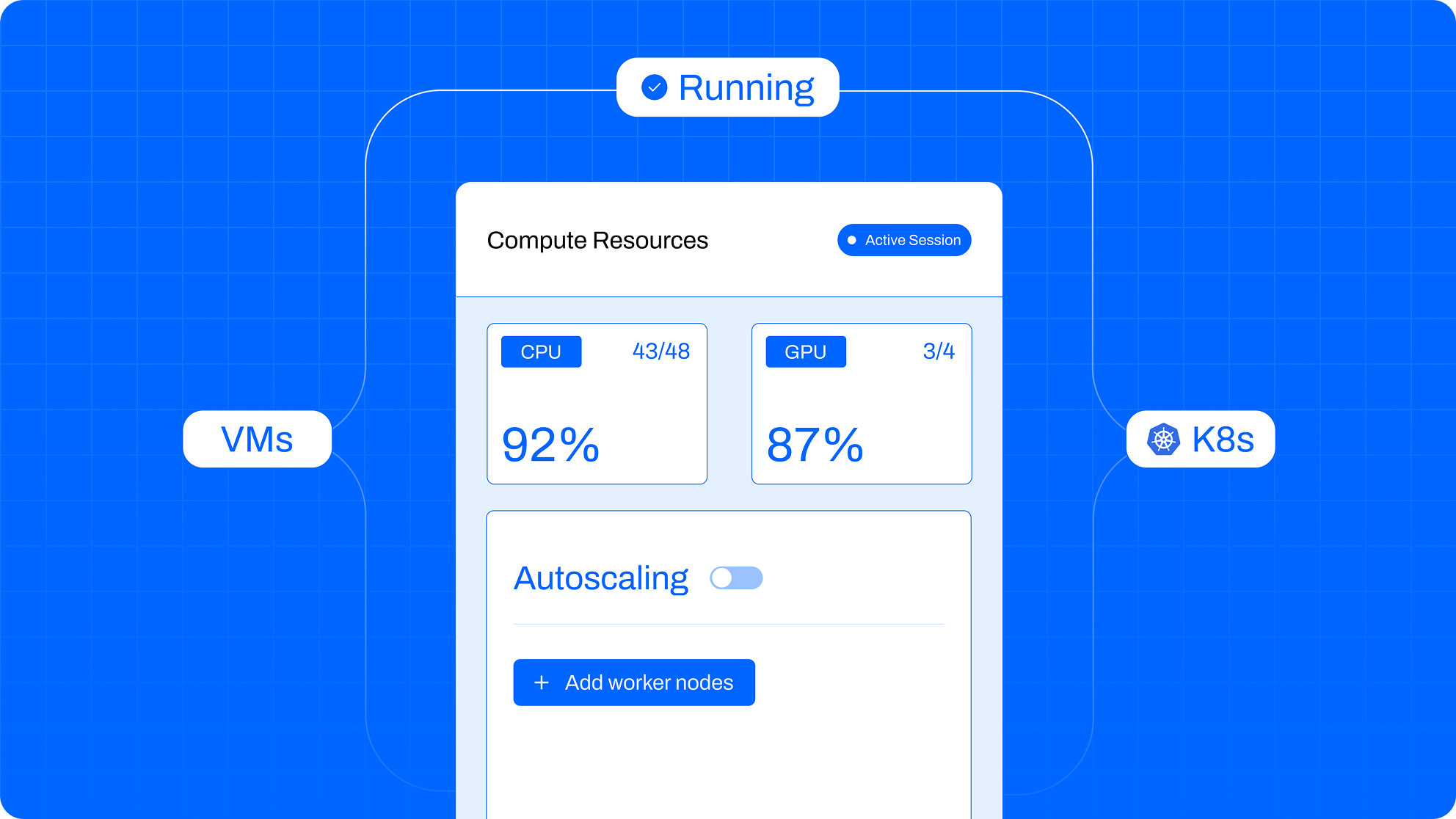
PRODUCTION RESILIENCE
Deploy Anywhere. Scale Reliably.
Deploy fault-tolerant Ray clusters in your cloud of choice with built-in resilience, auto-scaling, and no manual ops.
Fault Tolerant. Heterogeneous (CPU/GPU) VM or K8s cluster deployments with proactive unhealthy node draining and replacement
Zero-downtime upgrades. Upgrade with confidence using built-in rollback and seamless transitions.
Monitoring & Alerting. Managed Prometheus and Grafana dashboards, backed by persistent logs.
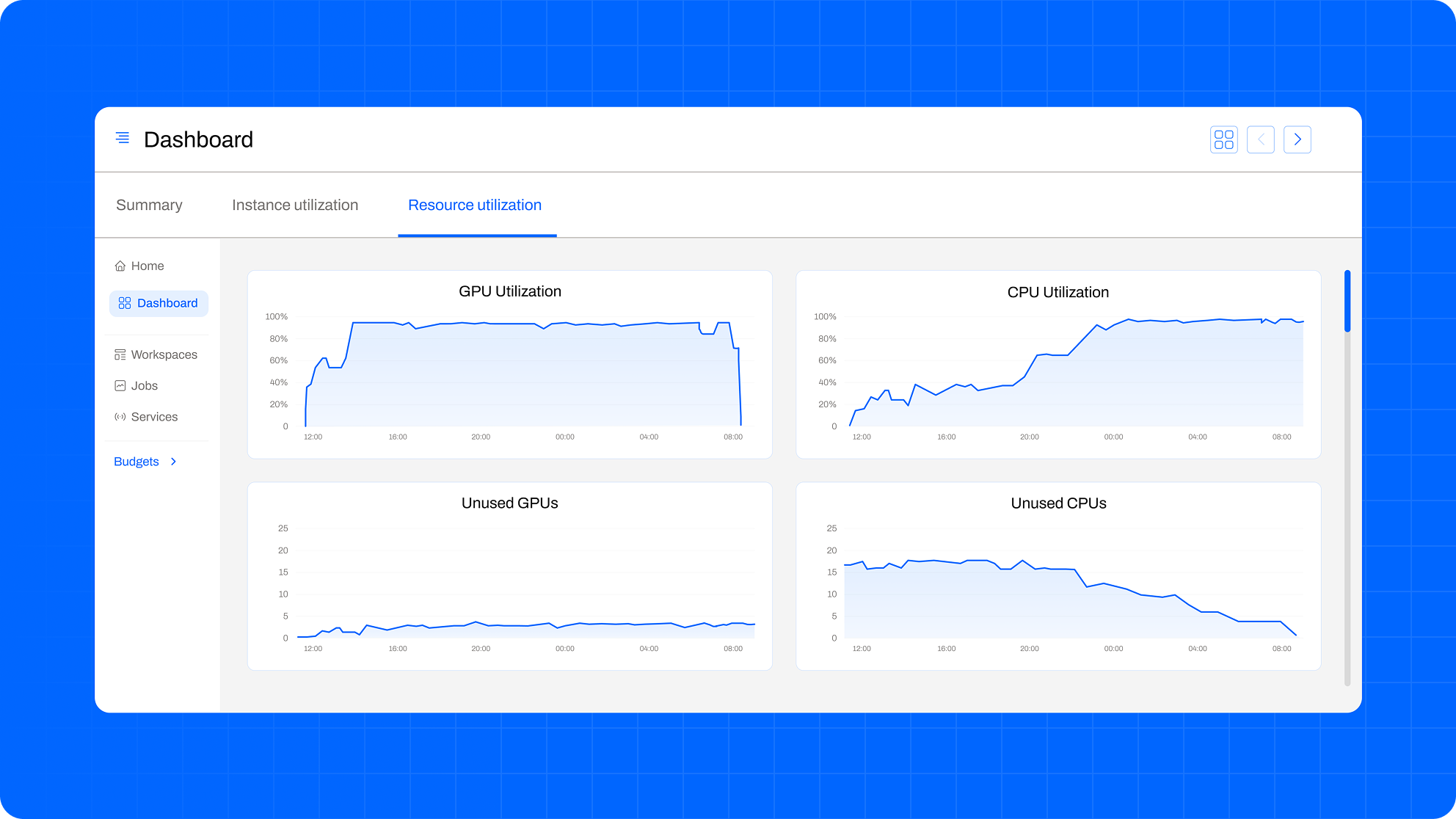
COST EFFICIENCY
Keep GPUs Busy – and Budgets Lean
Boost performance with Anyscale optimizations. Efficiently manage jobs or users with built-in governance and cost controls.
RayTurbo. Proprietary optimizations for every stage of the AI pipeline, from data preparation to training and inference.
Spot Instances. Reduce costs with reliable spot instance management, orchestration, and fall back to on-demand.
Cost Governance. Monitor usage across teams and keep costs in check with budgets and quotas.
One Platform. Every AI Workload.
From data prep to inference — if it’s Python, it runs better with Ray on Anyscale.
LLM training and inference
Fine-tune an LLM to perform batch inference and online serving for entity recognition.
Audio batch inference
Use LLMs as judges to curate and filter audio datasets for quality and relevance.
Deploy LLMs
Deploy base models, LoRA adapters, and embedding models with optimized Ray LLM.
Fine-tune LLMs with LLaMA-Factory on Anyscale
Fine-tuning LLMs with open source libraries and Ray.
Built with Ray. Deployed on Anyscale.
See how leading organizations take AI to production
12x
faster iteration to deliver over 100+ production models
5x
faster iteration for AI workloads

Wenyue Liu
Senior ML Platform Engineer
“Ray and Anyscale aligned with our vision: to iterate faster, scale smarter, and operate more efficiently.”

Sarah Sachs
Engineering Leader, AI Modeling
"We chose Anyscale not just for what we needed today, but for where we know we’re heading. As our AI workloads grow more complex, Anyscale gives us the infrastructure to scale without limits."
99%
reduction in cost
13x
faster model loading
The Team Behind Ray –
On Your Team
Built by the creators of Ray.
Supported by the people who know it best.
With Anyscale, you don’t just get a platform — you get a partner. Our team works hands-on with yours to troubleshoot, tune, and scale every part Ray-based platform, whether you're launching your first cluster or operating a large-scale deployment.

Try Anyscale Today
Unlock your potential – run AI and other Python applications on your cloud or on our fully-managed compute platform.